In the realm of deep learning, the success of models is heavily predicated on the quality of the data on which they are trained. Large datasets are imperative, as they provide the necessary breadth for models to learn effectively; however, the presence of label noise poses a significant challenge. Label noise arises when there are inaccuracies in the dataset labels, whether due to human error, data collection issues, or other factors. These discrepancies can lead to a detrimental decrease in the model’s ability to classify data accurately, particularly during the testing phase, ultimately affecting real-world applications across various industries.
Introducing Adaptive-k: A Novel Solution
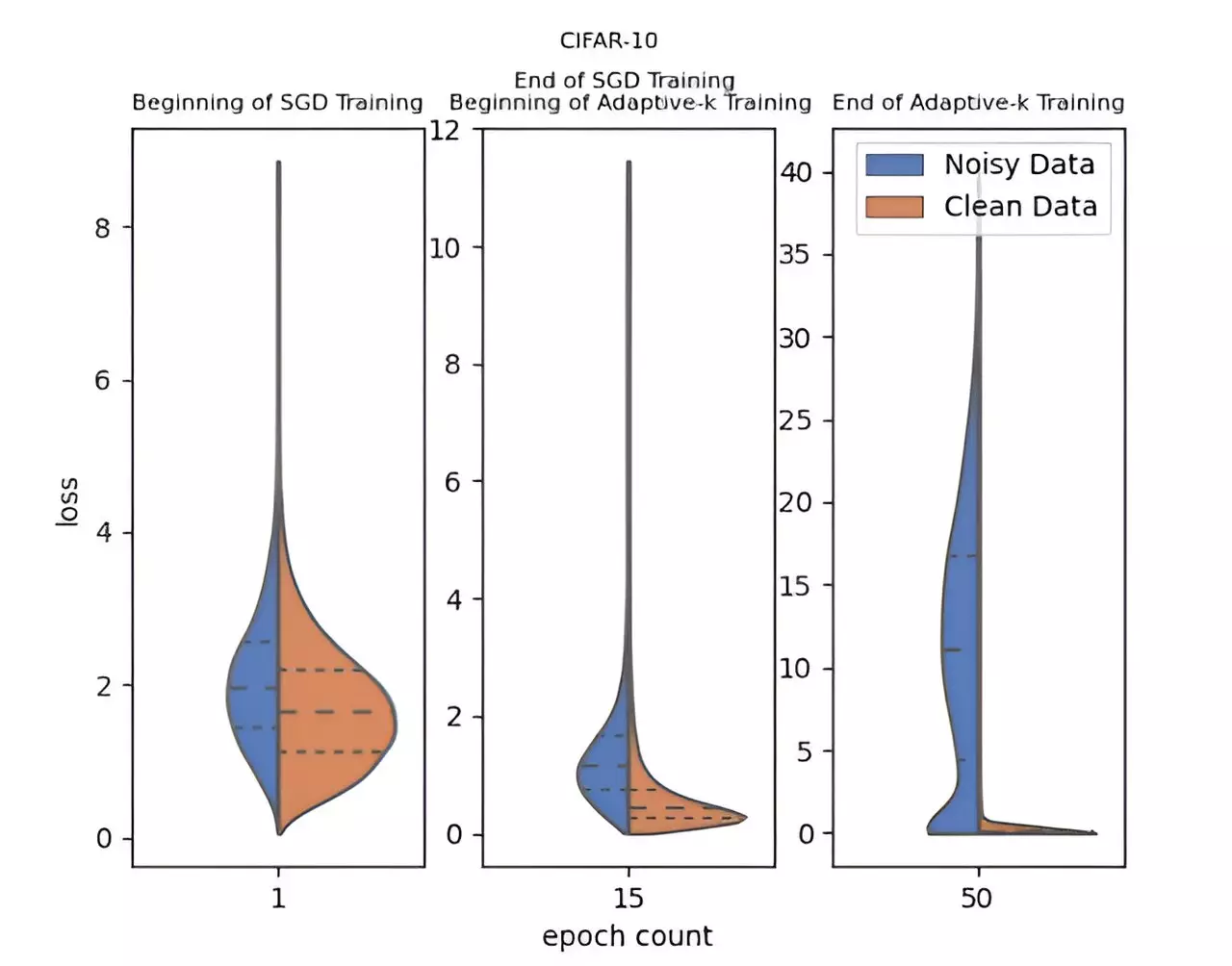
In light of these challenges, a team of researchers from Yildiz Technical University, including Enes Dedeoglu, H. Toprak Kesgin, and Prof. Dr. M. Fatih Amasyali, has innovated a new method named Adaptive-k. This approach stands out due to its dynamic mechanism for selecting samples during the optimization process, allowing for an effective differentiation between clean and noisy data points. This adaptability is crucial, as it circumvents the need for any prior knowledge regarding the level of noise within the dataset or the necessity for additional model training sessions, thus streamlining the process and enhancing efficiency.
The scientific implications of Adaptive-k are profound, as evidenced by the research published in the *Frontiers of Computer Science*. The method was rigorously tested against a variety of popular algorithms, including Vanilla, MKL (Multi-Kernel Learning), Vanilla-MKL, and Trimloss. Furthermore, the performance of Adaptive-k was juxtaposed with the ‘Oracle’ method, which represents an ideal scenario where all noisy samples are identified and excluded. The experimental data compiled from three different image datasets and four text datasets indicated a clear superiority of Adaptive-k in scenarios plagued by label noise, showcasing its capacity to yield accurate predictions without the extensive overhead typically associated with data cleanup.
One of the remarkable characteristics of Adaptive-k is its versatility; it is compatible with various optimization methods, including Stochastic Gradient Descent (SGD), Stochastic Gradient Descent with Momentum (SGDM), and Adam. This compatibility not only enhances its adoptability in existing systems but also enriches the potential for further research and application within this domain. Future research directives will likely focus on refining the Adaptive-k method, potentially exploring new applications across diverse fields, thereby enhancing model training processes significantly.
The introduction of Adaptive-k marks a pivotal advancement in addressing the label noise problem within deep learning. As models increasingly permeate various sectors, from healthcare to finance, the ability to train on noisy datasets without incurring accuracy penalties will be indispensable, paving the way for more reliable AI applications.
Leave a Reply