In the realm of artificial intelligence (AI), models like ChatGPT thrive on vast amounts of data processed through intricate algorithms and machine learning techniques. As the demand for computational power escalates in handling extensive datasets, so too do the challenges associated with traditional data-processing methodologies. One of the most significant bottlenecks encountered is the von Neumann bottleneck, a limitation that arises from the architecture of conventional computing systems. This bottleneck restricts the efficiency of data transfer between the processor and memory, stalling the data-processing capabilities essential for advanced AI applications.
The von Neumann architecture, named after the mathematician John von Neumann, has long been the cornerstone of computer design. It separates memory and processing units, which can lead to slow data movement and a mismatch between data transfer speeds and processing capability. As datasets grow exponentially, this misalignment inhibits the potential of AI to perform complex tasks efficiently, necessitating innovative solutions.
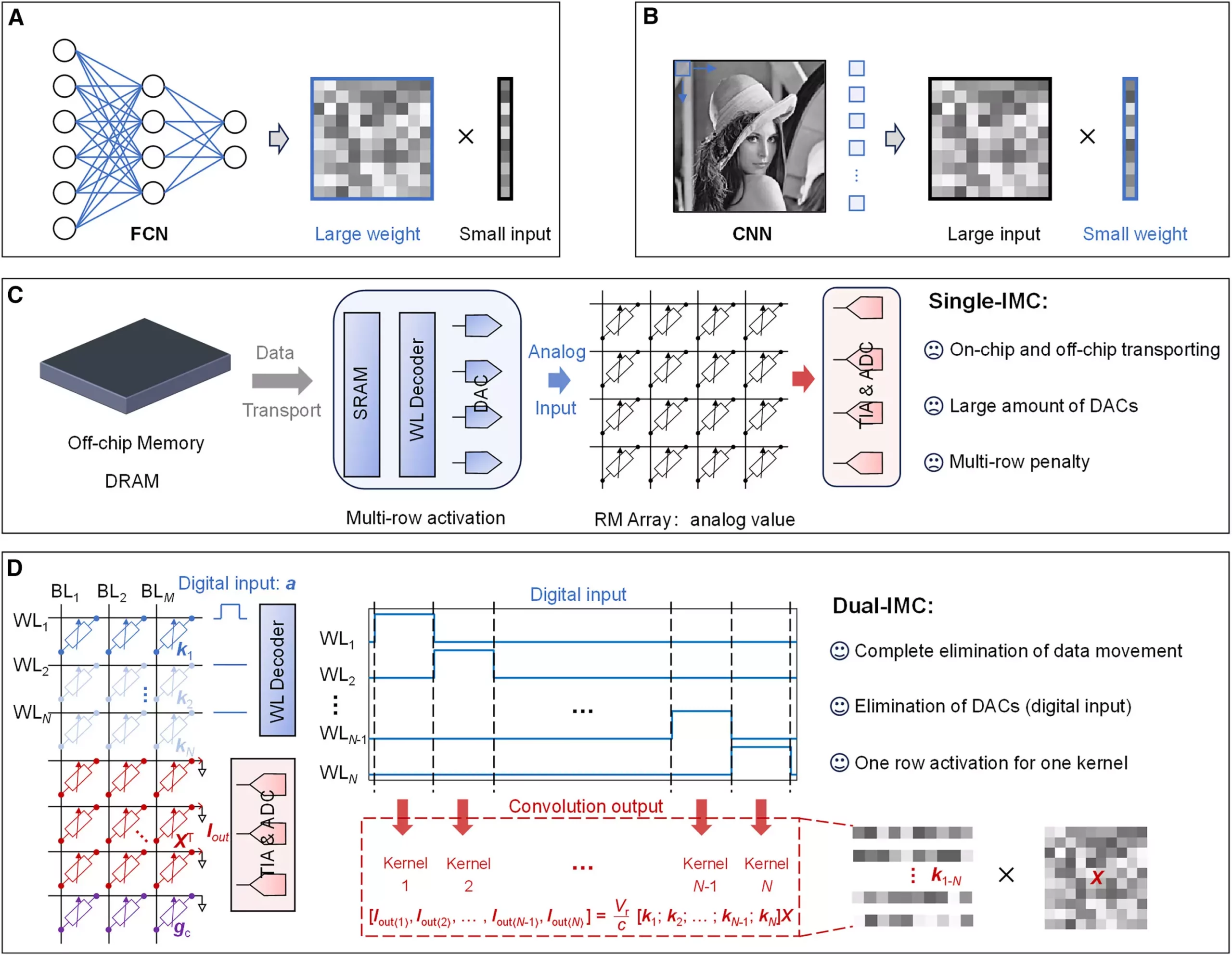
In a groundbreaking study led by Professor Sun Zhong and his team from Peking University, a remarkable alternative called the dual-in-memory computing (dual-IMC) scheme has emerged, addressing the core issues represented by the von Neumann bottleneck. Published in the journal Device on September 12, 2024, this pioneering research aims to revolutionize the efficiency of machine learning processes through advanced data-handling techniques.
Traditionally, many machine learning models rely heavily on operations like matrix-vector multiplication (MVM) to train neural networks. These networks are inspired by the human brain’s architecture, allowing them to learn and make decisions based on complex input data. However, as the scale and complexity of datasets increase, the slow transfer of data between on-chip and off-chip memory often stifles performance. The dual-IMC scheme proposes a shift in this paradigm by enabling computations to occur entirely in-memory.
The dual-IMC scheme marks a significant advancement by storing both the weight and input data of neural networks within the same memory array. This innovative structure allows the system to perform data operations entirely in-memory, effectively minimizing the need for data transferring. The benefits of this revolutionary approach are manifold:
1. **Increased Efficiency**: By keeping computations within memory, the dual-IMC method minimizes reliance on traditional off-chip memory (dynamic random-access memory or DRAM) and on-chip memory (static random-access memory or SRAM). This leads to faster processing capabilities, reducing the time and energy expenses associated with moving data around.
2. **Optimized Performance**: The dual-IMC scheme eliminates the latency caused by data movements, which are often bottlenecks in conventional systems. By performing MVM operations directly within memory, the system can operate with enhanced speed and responsiveness, allowing for more scalable AI applications.
3. **Cost Reduction**: One of the notable advantages of the dual-IMC model is its potential to decrease production costs. The single-IMC implementation requires the use of digital-to-analog converters (DACs), which not only consume power but also occupy a significant amount of chip area. With dual-IMC, the elimination of DACs leads to savings in chip design, power consumption, and operational latency.
As the digital landscape evolves, the capabilities of data processing and machine learning will play an increasingly critical role in a wide range of sectors, from healthcare to autonomous systems and beyond. The dual-IMC research stands at the forefront of this transformation, presenting a fresh approach that redefines how AI models interact with data. Researchers and industry professionals alike should pay close attention to this development, as it holds the promise of unlocking new possibilities in computing architecture and artificial intelligence.
The dual-IMC scheme developed by Professor Sun Zhong and his colleagues is not merely an incremental improvement; it could signify a paradigm shift in how we approach data processing in AI. By confronting the systemic challenges of traditional computing architectures, this innovative solution heralds a new era of efficiency, performance, and cost-effectiveness in the world of artificial intelligence. As the study suggests, the implications of these findings may extend far beyond the confines of academia, paving the way for the next generation of intelligent systems.
Leave a Reply