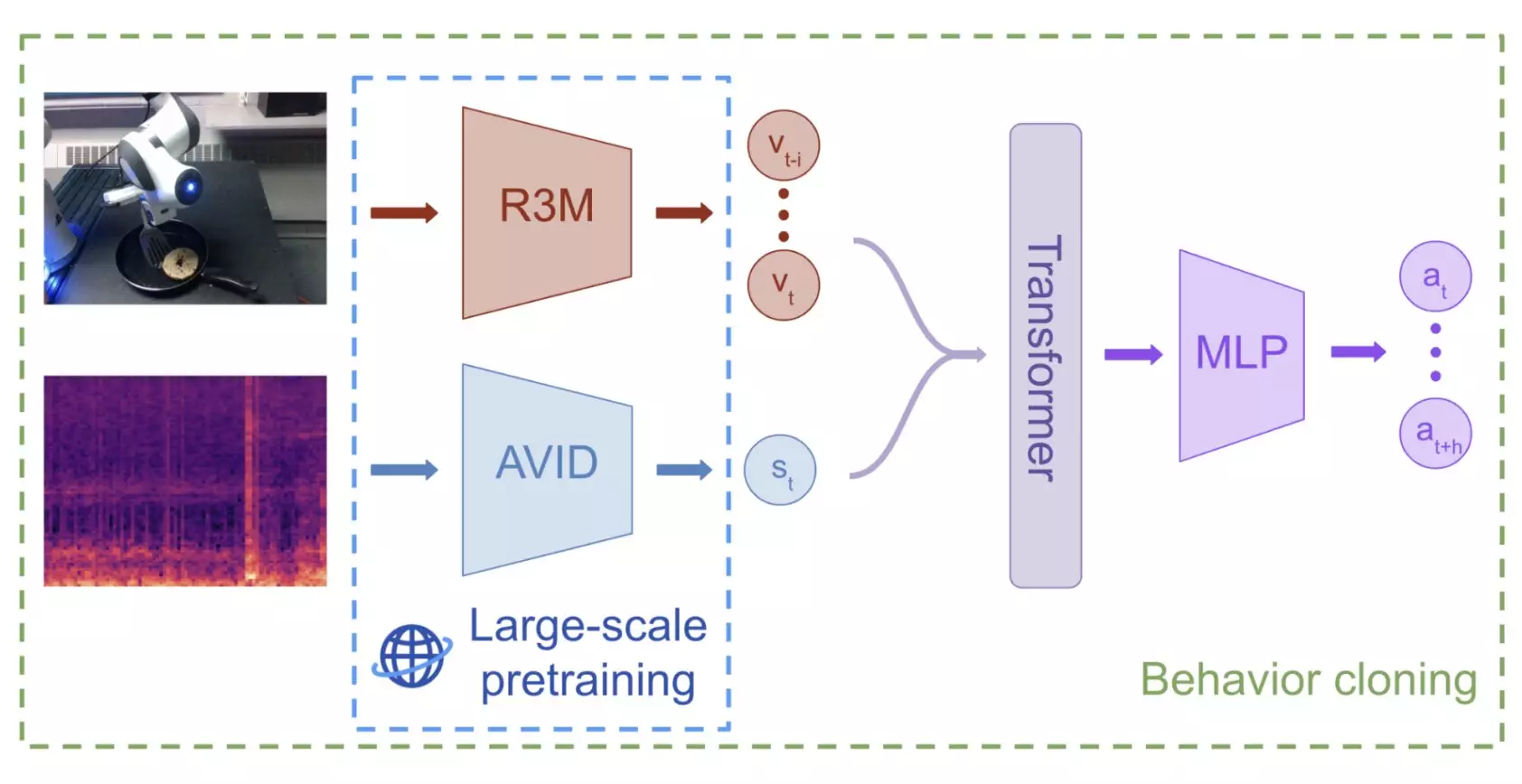
Robots are increasingly being expected to perform a wide range of tasks in various environments, including home settings, offices, and public spaces. One critical aspect that determines the effectiveness of robots in carrying out these tasks is their ability to grasp and manipulate objects with precision. In recent years, developers have been exploring machine learning-based models to enhance the object manipulation skills of robots. While some of these models have shown promising results, they often require extensive pre-training on large datasets to perform well. Typically, these datasets consist of visual data such as annotated images and video footage captured by cameras. However, researchers at Carnegie Mellon University and Olin College of Engineering took a different approach by considering the use of audio data, specifically from contact microphones, to train machine learning models for robot manipulation.
In their recent study, Jared Mejia, Victoria Dean, and their collaborators focused on pre-training a self-supervised machine learning model on audio-visual representations extracted from the Audioset dataset. The Audioset dataset contains over 2 million 10-second video clips of various sounds and music collected from the internet. The researchers applied the audio-visual instance discrimination (AVID) technique to teach the model to differentiate between different types of audio-visual data. They then conducted a series of tests where a robot was tasked with real-world manipulation tasks, with a maximum of 60 demonstrations available for each task.
The results of the study were highly promising, as the model outperformed policies that relied solely on visual data for robot manipulation tasks. This was particularly evident in scenarios where the objects and environments were significantly different from those included in the training data. The researchers highlighted the unique advantage of using contact microphones to capture audio-based information, allowing them to leverage large-scale audio-visual pretraining to enhance the robot’s manipulation performance. This innovative approach marks the first of its kind to utilize multi-sensory pre-training for robotic manipulation.
Looking ahead, Mejia, Dean, and their colleagues believe that their study could pave the way for more advanced robot manipulation techniques using pre-trained multimodal machine learning models. The proposed approach holds immense potential for further refinement and testing across a wider range of real-world manipulation tasks. Future research endeavors could delve into identifying the key properties of pre-training datasets that are most conducive to learning audio-visual representations for manipulation policies, thus pushing the boundaries of what is currently achievable in the field of robotics.
The exploration of audio data in training machine learning models for robot manipulation represents a significant advancement in the quest for enhancing the capabilities of robotic systems. By harnessing the power of contact microphones and innovative pre-training techniques, researchers are unlocking new possibilities for robots to perform complex manipulation tasks with greater efficiency and accuracy. As technology continues to evolve, the fusion of audio and visual data in training machine learning models is poised to revolutionize the field of robotics and drive unprecedented advancements in automation and artificial intelligence.
Leave a Reply